Big Data e Artificial Intelligence applicati alla gestione del Rischio di Credito
Partiamo dalle basi. Entrato prepotentemente nella nostra quotidianità, Big Data è uno di quei termini che moltissimi usano ma pochi davvero ne conoscono il significato.
Cosa sono davvero questi Big Data? Comunemente, per Big Data si intende una raccolta di dati così estesa in termini di volume, velocità, varietà e veridicità, da richiedere tecnologie di analisi e metodi specifici per l'estrazione del valore, ovvero di quei dati significativi per il proprio interesse.
Per fare questo, oltre ad un approccio completamente nuovo, vengono sviluppati ed utilizzati strumenti non convenzionali per estrapolare, gestire e processare le informazioni entro un tempo ragionevole: il Machine Learning, ovvero la capacità di apprendimento automatico da parte di una macchina.
Nel caso di modefinance, la gestione del Rischio di Credito è il settore d’interesse principale: il fine ultimo dell’analisi dei Big Data è determinare la probabilità di default, il fido commerciale e il rating di un determinato ente (azienda, assicurazione o banca).
Il Boom dei Big Data
Se un tempo i dati di input erano soltanto le informazioni pubbliche delle aziende (ad esempio i bilanci depositati), con la rapida evoluzione delle tecnologie si è potuta aumentare a dismisura questa mole di informazioni, ora Big Data, analizzata attraverso appropriati metodi. Le odierne risorse computazionali, in continua espansione, permettono di mettere in relazione i più disparati elementi, tra i quali di significativi si riportano l’andamento del settore di appartenenza, il posizionamento geografico, le news, i comportamenti sui social network, le relazioni del management e dei soci, ecc.
Ma come si mettono in relazione queste informazioni? Come vengono analizzate e quale importanza rappresentano all’interno della valutazione di una probabilità di default?
Modelli numerici
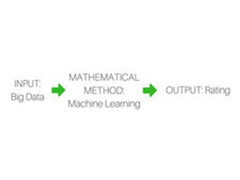
Ciò che sta alla base di questo percorso di analisi è il modello matematico numerico. Un modello è l’insieme di regole codificate in un preciso procedimento, e descrive la probabilità di evoluzione di un fenomeno sulla base di dati iniziali, input, restituendo dei dati finali, output. Quanto più precisa ed accurata la risposta, tanto più potente la tecnologia moderna computazionale (dev’essere in grado di elaborare tutti i dati e monitorarli costantemente).
Nel caso della gestione del Rischio di Credito, questo modello numerico ci da la possibilità di restituire una probabilità di default aggiornata in tempo reale: ogni qual volta una o più di queste informazioni di input cambiano, viene riclassificata all’interno del motore e va ad incidere (ed eventualmente modificare) la probabilità di default di un dato ente.
Qui si inserisce l’Intelligenza Artificiale, e nello specifico il Machine Learning: se un tempo i ricercatori creavano il modello pre-configurato e, tramite una metodologia automatizzata, definivano i parametri in modo da realizzare la relazione, ora i modelli sono rappresentati da algoritmi che si auto-adattano ai dati.
Uno dei modelli più utilizzati di Machine Learning è la rete neurale, un modello matematico composto da "neuroni" artificiali. Senza modelli prestabiliti, è la rete neurale a processare le informazioni, adattandosi a ricostruire il modello che passa tra dati di input e dati di output.
Analytics
Uno degli elementi principali nella gestione del Rischio di Credito, oltre alla possibilità di valutare il rating di una determinata azienda o banca, è rappresentato dal determinare quali siano le dinamiche che hanno causato quella valutazione, e integrare poi queste informazioni a livello settoriale/geografico o sulla base di altri parametri utili. Per far questo è fondamentale l’uso degli Analytics.
Per comprendere come e perché si arriva ai risultati finali, e qual è la relazione esistente tra input e output, si adottano una serie di metodologie statistiche che hanno una rappresentazione grafica. Una di queste è la Self Organizing Map, che va a selezionare e raggruppare elementi omogenei in un insieme di dati.
Tutte queste metodologie sono di derivazione statistica: ciò significa che, seppur molto accurate, vanno a studiare l’andamento generale della massa di informazioni, e possono perdere la singolarità di una posizione; ciò significherebbe ottenere una valutazione generale corretta ma con la possibilità di sbagliare il singolo caso. Il rating, dunque, si avvale sì di questo studio statistico, ma non può permettersi di perdere la singola posizione (che è la cosa più interessante), e dunque c’è un passaggio ulteriore: la validazione della singola posizione.
Per superare questa difficoltà, modefinance ha sviluppato il sistema innovativo MORE: un modello numerico in grado di simulare, adattando le singole tecnologie, il comportamento normale di un analista finanziario e fornire un risultato realistico, affidabile e certificato.
per imparare a valutare
finanziariamente partner,
competitor e clienti




